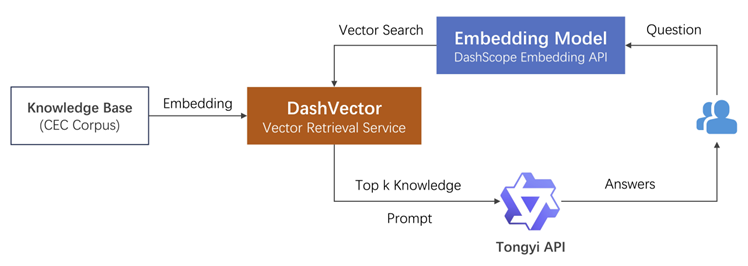
在阿里的灵积模型中嵌入垂直领域知识库 你的api key建议直接加入环境变量中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from http import HTTPStatus import dashscope def sample_sync_call(): prompt_text = '用萝卜、土豆、茄子做饭,给我个菜谱。' resp = dashscope.Generation.call( model='qwen-turbo', prompt=prompt_text ) # The response status_code is HTTPStatus.OK indicate success, # otherwise indicate request is failed, you can get error code # and message from code and message. if resp.status_code == HTTPStatus.OK: print(resp.output) # The output text print(resp.usage) # The usage information else: print(resp.code) # The error code. print(resp.message) # The error message. sample_sync_call()
embedding
本地知识库的向量化。通过文本向量模型将其转化为高质量低维度的向量数据,再写入DashVector向量检索服务。这里数据的向量化我们采用了灵积模型服务上的Embedding API实现。
相关知识点的提取。将提问文本向量化后,通过DashVector提取相关知识点的原文。
构造Prompt进行提问。将相关知识点作为“限定上下文+提问” 一起作为prompt询问通义千问。
本地知识库的向量化 dashscope.api_key,dashvector的api_key和endpoint需要写上你自己的,加载预料处的路径也改为你数据集的目录路径。batch_size根据自己需求调整。我这里用的数据集是从“人人都是产品经理”上爬下来的文章。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import os import dashscope from dashscope import TextEmbedding import dashvector from dashvector import Client, Doc def prepare_data(path, batch_size=25): batch_docs = [] for file in os.listdir(path): with open(path + '/' + file, 'r', encoding='utf-8') as f: batch_docs.append(f.read()) if len(batch_docs) == batch_size: yield batch_docs batch_docs = [] if batch_docs: yield batch_docs def generate_embeddings(news): rsp = TextEmbedding.call( model=TextEmbedding.Models.text_embedding_v1, input=news ) embeddings = [record['embedding'] for record in rsp.output['embeddings']] return embeddings if isinstance(news, list) else embeddings[0] if __name__ == '__main__': dashscope.api_key = '' # 初始化 client client = dashvector.Client( api_key='', endpoint='' ) assert client # 创建集合:指定集合名称和向量维度, text_embedding_v1 模型产生的向量统一为 1536 维 rsp = client.create('product', 1536) assert rsp # 加载语料 id = 0 collection = client.get('product') for news in list(prepare_data('knowledgedata/PM-data-master/woshipm.com')): print(news) ids = [id + i for i, _ in enumerate(news)] id += len(news) vectors = generate_embeddings(news) # 写入 dashvector 构建索引 rsp = collection.upsert( [ Doc(id=str(id), vector=vector, fields={"raw": doc}) for id, vector, doc in zip(ids, vectors, news) ] ) assert rsp
知识点的提取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import dashvector from dashvector import Client from dashvector import Doc from embedding import generate_embeddings def search_relevant_news(question): # 初始化 dashvector client client = dashvector.Client( api_key='', endpoint='' ) assert client # 获取刚刚存入的集合 collection = client.get('product') assert collection # 向量检索:指定 topk = 1 rsp = collection.query(generate_embeddings(question), output_fields=['raw'],topk=1) assert rsp return rsp.output[0].fields['raw'] question = input("请输入问题:") print(search_relevant_news(question))
构造Prompt进行提问 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import dashscope from http import HTTPStatus import os import webbrowser import dashvector from dashvector import Client from dashvector import Doc from embedding import generate_embeddings def generate_response(prompt): response_generator = dashscope.Generation.call( model='chatglm3-6b', prompt=prompt, stream=True, top_p=0.8) head_idx = 0 print("\n") for resp in response_generator: paragraph = resp.output['text'] # print("\r%s" % paragraph[head_idx:len(paragraph)], end='') if(paragraph.rfind('\n') != -1): head_idx = paragraph.rfind('\n') + 1 if resp.status_code == HTTPStatus.OK: return resp.output.text # The output text print(resp.usage) # The usage information else: print(resp.code) # The error code. print(resp.message) # The error message. def search_relevant_news(question): # 初始化 dashvector client client = dashvector.Client( api_key='', endpoint='' ) assert client # 获取刚刚存入的集合 collection = client.get('product') assert collection # 向量检索:指定 topk = 1 rsp = collection.query(generate_embeddings(question), output_fields=['raw'],topk=1) assert rsp return rsp.output[0].fields['raw'] # 初始化对话历史列表 dialogue_history = [] while True: # 获取用户输入的对话内容 origin_user_input = input("\n\n请描述您的问题:") # 结束循环条件:用户未输入新对话 if not origin_user_input: break # 添加知识库参考 user_input = search_relevant_news(origin_user_input) + "\n请参考以上资料回答下列问题\n" + origin_user_input # print(user_input) # 将用户对话内容添加到历史记录中 dialogue_history.append(user_input) # 构建包含对话历史的新提示 prompt_text = "\n".join(dialogue_history) # 使用新的对话上下文生成回复 generated_response = generate_response(prompt_text) print(generated_response) # 获取当前工作目录 current_dir = os.getcwd() with open('answer.txt', 'w', encoding='utf-8') as f: f.write(generated_response) # 循环结束后,程序会在这里结束
如此一来,大模型就会根据你知识库的内容来回答你的问题
提问:需求分析怎么做
这是通过dashvector从知识库中检索到的内容
这是构造prompt后的对话
很明显大模型参考了知识库,然后根据问题回答